Raptor Innovation Summit 2026 — Registration is Live
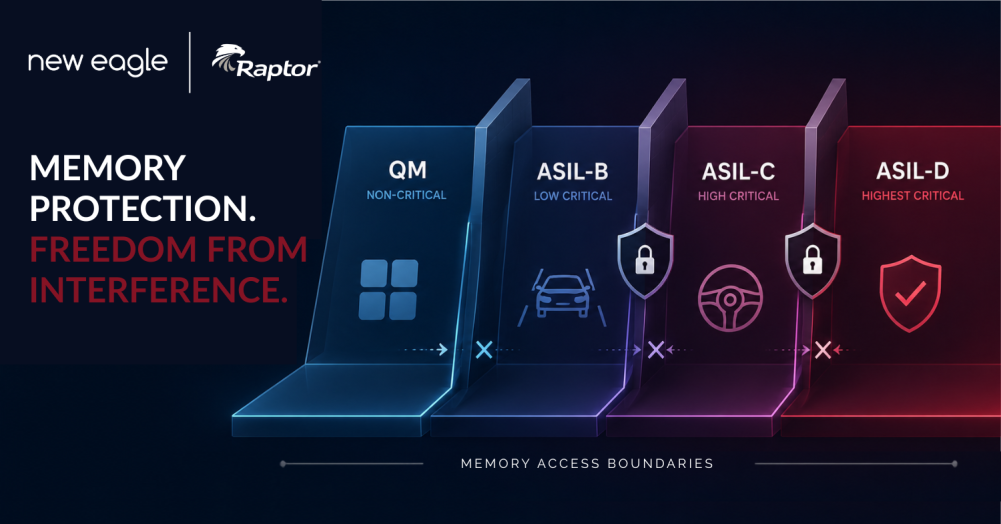
Freedom From Interference, Built In: Memory Protection Arrives With Raptor 2026a
Functional safety applications increasingly combine safety-critical (ASIL) and quality-managed (QM) software components on the same controller. This architecture can reduce …